La CTP3 de PowerPivot for Excel 2010 est disponible à l'adresse suivante.
Bien qu'annoncée hier, il semble que le fichier ait été disponible depuis quelque temps (voir date de parution du fichier).
Bons tests!
jeudi 19 novembre 2009
lundi 16 novembre 2009
L'Echo Pilote: Nouveau Blog BI MS en Français
Découvrez un nouveau blog consacré à la BI Microsoft et écrit en français: L'Echo Pilote.
Lancé par les équipes Microsoft France, ses objectifs sont les suivants:
- Démystifier ce qu’est le décisionnel
- Partager des conseils d’utilisation
- Créer une zone d’échange
- Fournir gratuitement des accélérateurs prêts à l’emploi
dimanche 15 novembre 2009
PowerPivot: Point de vue Fonctionnel
Introduction
Depuis plusieurs années déjà, Excel possède une fonctionnalité permettant de créer des tableaux croisés dynamiques (PivotTables). Qu'ils soient fondés sur un cube de données, une base de données relationnelle ou même un onglet du fichier Excel, ces tableaux croisés dynamiques vont permettre d'analyser des données de façon agrégée (Somme, Moyenne, Nombre de lignes...) et de ventiler ces résultats par un ou plusieurs champs.
Exemple de PivotTable classique dans Excel:

Bien que très utile, cette fonctionnalité peut présenter un certain nombre de limitations:
- Par exemple vous ne pourrez pas faire de tableaux croisés regroupant les données de différentes sources ni même de plusieurs tableaux d'un même document Excel
- Si les données proviennent d'une base de données relationnelle et si la volumétrie est importante alors vous aurez des temps de réponse assez longs. C'est la raison pour laquelle on construit des cubes de données (OLAP) qui permettent de regrouper des données hétérogènes et de les restituer dans des temps de réponse très courts grâce à un système de pré-calcul des agrégations. Cependant, la construction de ces cubes est un projet à part entière qui nécessite une modélisation et des connaissances techniques, et il arrive que certains éléments dont vous pouvez avoir besoin tout de suite pour vos analyses ne soient pas encore présents dans ces cubes de données.
Le produit
PowerPivot est un add-in gratuit d'Excel 2010 qui permet donc de dépasser les limites des PivotTables classiques. Grâce à un système d'analyse en mémoire (In-Memory), de grandes quantités de données vont pouvoir être manipulées avec des temps de réponse très courts. Là où avec un PivotTable classique vous manipuliez des milliers de lignes, avec PowerPivot ce seront des millions. L'autre atout de cet add-in est de pouvoir aller chercher des données dans des sources diverses et les croiser.
Onglet PowerPivot dans Excel 2010:

L'utilisation de ce composant peut se résumer en 2 grandes étapes:
- Chargement des données
- Création des tableaux croisés (ou graphes)
Chargement des données
Les types de sources de données disponibles sont assez variés:
- Fichier plat
- Base relationnelle
- Base multidimentionnelle (Cube OLAP)
- Flux RSS
- Rapport Reporting Services (SSRS)
- Toute donnée pouvant être copiée, d'une page web par exemple (Crtl C , Crtl V)
Les données pouvant donc venir de différentes sources, un éditeur de "relations" permet de les lier entre elles.
Environnement de chargement de données de PowerPivot: 
Le grand avantage de l'outil par rapport à ses concurrents est sa simplicité. Il est en effet possible de l'utiliser sans connaissances techniques particulières. Aucun script ou code n'est présenté au créateur du rapport.
Il est cependant possible d'aller plus loin si on le souhaite en créant de nouveaux champs calculés au sein de la structure de données. On utilise pour cela un langage baptisé DAX (Data Analysis Expression) qui a une structure assez proche des fonctions Excel, enrichie de fonctions spécifiques à un environnement multidimensionnel.
Les données récupérées seront stockées en mémoire, puis dans le fichier Excel au moment de la sauvegarde de celui ci (compressées). Cela permet entre autre de pouvoir travailler en mode déconnecté à partir du moment où les données sont chargées.
Création des tableaux croisés et des graphes
Une fois les données chargées, reste à créer les tableaux croisés et les graphes qui serviront à l'analyse des données. Le tout sera appelé un tableau de bord. L'interface de création est similaire à celle des PivotTables classiques.
Vous pourrez également profiter des Slicers, nouvel élément d'Excel 2010 qui permet d'afficher la liste des membres d'un champ et d'appliquer des filtres sur les rapports suivant les sélections effectuées. L'atout de ces slicers est qu'il sont liés les uns aux autres.
Exemple de tableau de bord PowerPivot avec Slicers:

Partage des fichiers PowerPivot
Après avoir chargé les données et créé les tableaux croisés et les graphes, il est possible de partager le fichier avec d'autres utilisateurs. Cela peut se faire via le portail d'entreprise "Sharepoint 2010". L'avantage est que cet environnement est sécurisé et peut être administré par le service informatique de l'entreprise.
L'autre avantage est que du coup, seule la personne développant les rapports doit avoir Excel 2010 d'installé sur son poste, les autres personnes consultant ce fichier via Sharepoint et le service en ligne d'Excel (Excel Services).
Liste des fichiers PowerPivot déployés dans Sharepoint 2010:

Conclusion
PowerPivot permet donc d'aller plus loin qu'avec les PivotTables classiques d'Excel. Pouvant gérer de gros volumes de données avec des temps de réponse très courts et peu de connaissances techniques, il permettra aux personnes fonctionnelles qui le souhaitent, d'être en avance de phase par rapport à l'IT en créant des tableaux de bord personnalisés intégrant des données pas encore mises à disposition par la DSI.
Exemple de tableau de bord PowerPivot dans un de mes billets précédents
A suivre, le point de vue IT du produit...
PowerPivot Fonctionnels / IT

A quelques jours de la sortie de la CTP3 de PowerPivot (livrée séparément de la CTP SQL Server 2008 R2), j'ai pensé qu'il serait intéressant d'écrire deux articles présentant le produit et les besoins auxquels il répond:
- Un qui décrit le produit d'un point de vue fonctionnel, comment une personne "non technique" va utiliser le produit et dans quel cas.
- Un deuxième article plus orienté IT qui précisera comment une personne "technique" pourra profiter de l'outil et en assurer l'administration et quel est son positionnement face à Analysis Services.
Je reçois beaucoup de questions sur le produit et j'espère que ces articles permettront d'y répondre.
Bonne lecture.
lundi 9 novembre 2009
Présentation de PowerPivot au GUSS
J'ai eu l'occasion de présenter PowerPivot (à l'époque appelé projet Gemini) lors de la dernière session du GUSS (Groupe des Utilisateurs francophones de Microsoft SQL Server). Ce fut notamment l'occasion de faire la démonstration de l'application "Analyse des vols au départ de l'aéroport Roissy Charles de Gaulle" que j'avais présenté dans un billet début septembre.
Je remercie Lionel Billon (Chef de produit SQL Server en France) et Christian Robert (MVP SQL Server) de m'avoir invité à leur session.
Le ppt de la présentation a été mis en ligne sur le site du groupe, n'hésitez pas à le consulter.
Je remercie Lionel Billon (Chef de produit SQL Server en France) et Christian Robert (MVP SQL Server) de m'avoir invité à leur session.
Le ppt de la présentation a été mis en ligne sur le site du groupe, n'hésitez pas à le consulter.
samedi 7 novembre 2009
PerformancePoint Services 2010 - Suite
Depuis mon dernier article présentant les nouveautés de PerformancePoint Services 2010, l'équipe du produit a commencé à diffuser des images du produit via son blog. On peut donc voir à quoi ressemblera l'interface de cette nouvelle version complètement intégrée à Sharepoint.
Interface PerformancePoint Services 2010:

Une nouveauté dont je n'ai pas beaucoup parlé dans mon dernier billet, mais qui a son importance, concerne les scorecards. La sélection des membres des dimensions affichées peut maintenant être dynamique (Children, Descendants etc.). Ainsi, si on prend l'exemple du scorecard ci dessous, si de nouveaux produits de type "Bikes" font leur apparition dans le cube, alors ils apparaîtront sur le scorecard. Ce n'était pas le cas dans la version 2007, les sélections étant fixes. Cette nouveautés vient donc répondre à un réel besoin que j'avais pu détecter en travaillant avec la version précédente.

A noter également la possibilité d'avoir plusieurs valeurs "Réelles" pour un KPI , le fait de pouvoir naviguer hierarchiquement dans le scorecard (DrillDown/Ûp, Expand/Collapse) et les nouvelles "calulated metrics".
Concernant le rapport "KPI Details" dont je vous parlais dans mon dernier billet, en voici un exemple concret ci dessous.

Enfin, les premières images du composant "Arbre de décomposition" de la version 2010, qui je vous le rappelle, est maintenant indépendant de Proclarity:
Reste maintenant à voir quelles sont les nouveautés au niveau du Dashboard Designer, l'application permettant de construire les tableaux de bord PerformancePoint. Et surtout, pouvoir tester le produit dès qu'une première version beta publique sera disponible.
Pour plus d'informations, n'hésitez pas à lire l'article de l'équipe du produit qui détaille les points que je vous ai présentés et d'où sont extraites les captures d'écran de ce billet.
samedi 24 octobre 2009
PerformancePoint Services 2010: Les nouveautés

Après un premier rapprochement sur le plan licensing en avril dernier, PerformancePoint et Sharepoint concrétisent leur union avec la sortie d'Office 14 (H1 2010).
Connu tout d'abord sous le nom "Busineess Scorecard Manager 2005" (BSM2005), puis intégré à PerformancePoint 2007 (Monitoring & Analytics), ce produit devient donc en 2010 un service Sharepoint à part entière et il a été dévoilé cette semaine à la Sharepoint Conference à Las Vegas. Les premières informations commencent donc à émerger, permettant d'entrevoir ce que proposera cette nouvelle version.
Les tableaux de bord: Les Dashboards
Du point de vu des tableaux de bords, la principale nouveauté est le type de graphique "arbre de décomposition" qui sera désormais disponible directement dans le dashboard designer, sans passer par Proclarity. On peut donc imaginer que leur intégration et notamment leur intéraction avec les filtres des dashboards sera améliorée. D'autres nouveaux types de graphiques devraient faire leur apparition; peut être des dérivés de Proclarity comme la carte de performances?
Exemple d'arbre de décomposition (PPS 2007):

Une des autres nouveautés est le rapport de type "KPI detail report". Ce composant pourra être relié à un scorecard ou à un Kpi pour afficher à l'utilisateur des métadata les concernants. Je n'ai pas encore vu d'image de ce composant mais j'imagine son utilité. C'est bien joli d'avoir un indicateur clé de performance avec ses valeurs cibles, réelles, tendances et icones...mais c'est encore mieux de savoir comment il est calculé et à quoi il correspond exactement. En général dans les projets j'étais souvent amené à créer un wiki sur le site sharepoint pour lister les KPI et leurs définitions. Il semble donc que ce soit désormais directement intégré aux dashboards...interessant!
Sinon, de manière plus générale, Microsoft nous annonce des améliorations sur les élements déjà existants tels que les filtres, les liens entre les rapports ou encore les scorecards (drilldown, hiérarchies dynamiques, calulated KPI)... à tester.
Exemple de Scorecard (PPS 2007):

Des nouveautés donc, mais aussi des retraits. Certains sont logiques, je pense notamment aux "Pivot Table" & "Pivot Chart" qui n'étaient présents dans PPS 2007 que pour rétro-compatibilité avec les dashboards BSM2005 et utilisaient les Office Web Components. Vous choisirez donc maintenant les "Analytics grids" et "Analytics charts" (ce qui était déjà conseillé en version 2007). A noter la disparition du "Trend chart". Ce type de rapport utilisait un algorithme de datamining (time series) pour proposer une tendance sur une période donnée. Assez sympa à montrer en démo, celui ci n'était finalement pas si utilisé que ça en projet et présentait même quelques limitations... Enfin, il n'y aura plus de sources de données de type "ODBC" donc plus de connexions possibles à des bases Oracle ou MySQL...
L'architecture du produit:
Vu de la lune, l'architecture du produit reste la même: Un front-end web, des services, le Dashboard Designer et une base de données pour les métadata. Mais la comparaison d'arrête là. L'intégration du produit en tant que service sharepoint change quand même pas mal de choses.
Premièrement, les services PerformancePoint ne font plus parti du Shared Service Provider (SSP) mais sont directement intégérés dans le Microsoft Sharepoint Foundation (nouveau nom de WSS).
Les métadata (Repository) des dashboards sont elles aussi stockées via Sharepoint. Par exemple, les datasources sont stockées dans des librairies de documents et le reste des éléments dans des listes Sharepoint.
Enfin, la sécurité est également gérée au niveau de Sharepoint. C'est en effet aux utilisateurs Sharepoint qu'on donnera des droits sur les éléments. Concernant les accès aux sources de données, on garde les deux modes: Soit une authentification partagée par tous (Unattended account), soit du cas par cas via l'utilisation d'un "secure store" qui permet d'éviter les problèmes de "double hop" et ainsi déviter l'utilisation de Kerberos.
Dernier "petit" détail, PerformancePoint étant un service de Sharepoint 2010, il ne tournera donc que sur des serveurs 64 bits...
Architecture de PerformancePoint Services 2010:

Src: http://technet.microsoft.com/en-us/library/ee661741(office.14).aspx
Conclusion
Cette Sharepoint Conference a donc été l'occasion pour Microsoft de dévoiler cette nouvelle version de PerformancePoint. Des sessions ont couvert la création de dasboards (basiques mais aussi avancés) ainsi que des méthodes de migration de dashboards PPS2007 vers PPS 2010. Si vous avez eu la chance d'assister à l'une de ces sessions, vos retours m'interessent. N'hésitez donc pas à laisser un commentaire ou à m'envoyer un email!
lundi 19 octobre 2009
"Gemini" devient "PowerPivot"

La nouvelle est tombée aujourd'hui à la Sharepoint Conference à Las Vegas: Le projet Gemini sortira donc officiellement sous le nom "Microsoft SQL Server PowerPivot for Excel 2010".
Un site web est dores et déjà disponible: http://www.powerpivot.com/
Vous y trouverez une vidéo de présentation du produit ainsi qu'un formulaire pour être averti de la sortie de la CTP3 du produit.
Un site web est dores et déjà disponible: http://www.powerpivot.com/
Vous y trouverez une vidéo de présentation du produit ainsi qu'un formulaire pour être averti de la sortie de la CTP3 du produit.
Il semblerait que le service permettant de partager les applications via Sharepoint portera le nom "PowerPivot for Sharepoint 2010"... à confirmer. C'est ce dernier service qui utilisera la nouvelle version de SQL Server 2008 R2.
samedi 17 octobre 2009
PerformancePoint Server 2007: Version finale (SP3)
L'ultime service pack de PerformancePoint Server 2007 est sorti, il s'agit du SP3.
Je vous avez déjà parlé de celui ci en début d'année dans un billet au moment du changement de roadmap BI chez Microsoft. C'est en effet une mise à jour assez spéciale puisque c'est la dernière concernant le produit dans sa version 2007 et notamment la version finale du module planning.
Ce service pack corrige un ensemble d'anomalies du logiciels mais apporte également quelques nouveautés:
Liens de téléchargement du SP3
Concernant le 3e module de PerformancePoint 2007, Proclarity, le SP3 est sorti un peu plus tôt cette semaine, voir le billet correspondant.
Prochaine étape, la découverte de PerformancePoint Services, version intégrée dans Sharepoint 2010 de PPS Monitoring et certains composants Proclarity, dévoilée la semaine prochaine à la Sharepoint conférence à Las Vegas... A suivre!
Je vous avez déjà parlé de celui ci en début d'année dans un billet au moment du changement de roadmap BI chez Microsoft. C'est en effet une mise à jour assez spéciale puisque c'est la dernière concernant le produit dans sa version 2007 et notamment la version finale du module planning.
Ce service pack corrige un ensemble d'anomalies du logiciels mais apporte également quelques nouveautés:
- Planning
Extension du calendrier au delà des 25 ans, gestion de la sécurité via la commande PPSCmd ou encore la soumission de détails concernant les lignes saisies.
- Monitoring
Liens de téléchargement du SP3
Concernant le 3e module de PerformancePoint 2007, Proclarity, le SP3 est sorti un peu plus tôt cette semaine, voir le billet correspondant.
Prochaine étape, la découverte de PerformancePoint Services, version intégrée dans Sharepoint 2010 de PPS Monitoring et certains composants Proclarity, dévoilée la semaine prochaine à la Sharepoint conférence à Las Vegas... A suivre!
mardi 13 octobre 2009
Proclarity 6.3 SP3 et Migration vers PerformancePoint Services
Le Service Pack 3 (SP3) de Proclarity 6.3 est disponible:
- Proclarity Analytics Server
- Proclarity Desktop Professional (Client lourd)
Dans le même temps, Chris Webb vient d'écrire un article concernant la migration des projets Proclarity 6.3 vers le futur PerformancePoint Services livré avec Sharepoint 2010 l'année prochaine. Visiblement aucun outils de migration ne sera proposé...surprenant!
"There will not yet be a migration from ProClarity 6.3 to PerformancePoint Services for SharePoint 2010. Customers can continue to use ProClarity throughout its current supported lifecycle date of July 2012 for mainstream and July 2017 for extended. We are still working on the roadmap for ProClarity but it is likely that you will not see a migration path until the O15 timeframe. "
Src: Alyson Powell Erwin (Microsoft)
Retrouvez l' article de Chris Webb ici (en anglais), il soulève des points importants!
mercredi 7 octobre 2009
Un Windows Café bientôt à Paris
J'en avais déjà eu vent grâce à Nadia (envoyée spéciale exilée à Seattle qui se reconnaîtra ;) ) et je suis passé devant un peu par hasard tout à l'heure; j'en profite donc pour partager l'information.
Microsoft va ouvrir un "Windows café" à Paris à l'occasion du lancement de Windows 7 le 22 Octobre prochain. Le principe est de profiter d'une pause café pour découvrir le nouveau système d'exploitation. Une opération marketing assez originale, puisque ce café ne restera ouvert que quelques semaines le temps du lancement.
Tel un Cyber Central Perk au coeur du quartier des Halles, ce lieu ne manquera pas d'attirer les curieux...ou tout simplement les accros à la caféine.
Actuellement en travaux, un slogan imprimé sur la vitrine invite ironiquement les passants à "surfer sur le trottoir en attendant"... Ouverture le 22 octobre, à suivre!

Adresse: 47 Boulevard de Sébastopol, 75001 Paris
Microsoft va ouvrir un "Windows café" à Paris à l'occasion du lancement de Windows 7 le 22 Octobre prochain. Le principe est de profiter d'une pause café pour découvrir le nouveau système d'exploitation. Une opération marketing assez originale, puisque ce café ne restera ouvert que quelques semaines le temps du lancement.
Tel un Cyber Central Perk au coeur du quartier des Halles, ce lieu ne manquera pas d'attirer les curieux...ou tout simplement les accros à la caféine.
Actuellement en travaux, un slogan imprimé sur la vitrine invite ironiquement les passants à "surfer sur le trottoir en attendant"... Ouverture le 22 octobre, à suivre!

Adresse: 47 Boulevard de Sébastopol, 75001 Paris
mardi 6 octobre 2009
Named Sets et Tableaux Croisés Asymétriques dans Excel 2010
Voilà maintenant quelques semaines que j'expérimente la nouvelle version 2010 d'Excel qui est pour l'instant en version bêta et dont la sortie est prévue l'année prochaine. Cette version présente quelques nouveautés pour l'analyse ad-hoc d'un cube Analysis Services. Vous avez peut être déjà lu des articles présentant les slicers qui sont une évolution phare. On retrouve également cette notion dans Gemini.
Une autre nouveauté de la version 2010 d'Excel est donc la possibilité de créer, sans add-in supplémentaire, des "Named sets". Ces jeux nommés ont pour but de permettre aux utilisateurs de se créer leurs propres ensembles de données qu'ils pourront réutiliser dans différents rapports. Par exemple, une personne en charge de différents sites d'une entreprise pourra se créer dans la dimension Géographie un named set "Mes sites" qui comprendra la liste des villes dont il s'occupe (Paris, Bordeaux et Biarritz par exemple). Ainsi, au lieu de resélectionner à chaque fois les villes qui l'interesse, cette personne pourra directement sélectionner son jeu nommé "Mes sites" dans ses futurs rapports. Ce n'est pas une notion nouvelle; ce type de fonctionnalité était déjà proposé dans des outils comme Proclarity ou certains Add-In Excel des versions précédentes. Il faut cependant souligner que cette fois ci, c'est une fonction native d'Excel.
Une autre nouveauté intéressante, liée puisqu'elle utilise les named sets, est la possibilité de créer des "Tableaux Croisés Asymétriques". Par exemple; en contrôle de gestion il arrive souvent qu'on ait besoin d'avoir des tableaux présentant en colonne un croisement entre une date et des scénarios précis différents suivant la date (S1 2009 et Scénario Réel uniquement, S2 2009 et Scénario Budget uniquement). Ce tableau est asymétrique car il n'affiche pas tous les scénarios existant sous une date précise comme le ferait par défaut un tableau croisé dynamique: (S1 2009 et Scénarios Réels et Budget, S2 2009 et Scénarios Réels et Budget).
Enfin, pour les utilisateurs les plus avancés il est possible d'écrire directement ses named sets en MDX.
Tous ces points font l'objet d'un très bon post bien détaillé, publié (en anglais) par l'équipe du produit.
Une autre nouveauté de la version 2010 d'Excel est donc la possibilité de créer, sans add-in supplémentaire, des "Named sets". Ces jeux nommés ont pour but de permettre aux utilisateurs de se créer leurs propres ensembles de données qu'ils pourront réutiliser dans différents rapports. Par exemple, une personne en charge de différents sites d'une entreprise pourra se créer dans la dimension Géographie un named set "Mes sites" qui comprendra la liste des villes dont il s'occupe (Paris, Bordeaux et Biarritz par exemple). Ainsi, au lieu de resélectionner à chaque fois les villes qui l'interesse, cette personne pourra directement sélectionner son jeu nommé "Mes sites" dans ses futurs rapports. Ce n'est pas une notion nouvelle; ce type de fonctionnalité était déjà proposé dans des outils comme Proclarity ou certains Add-In Excel des versions précédentes. Il faut cependant souligner que cette fois ci, c'est une fonction native d'Excel.
Une autre nouveauté intéressante, liée puisqu'elle utilise les named sets, est la possibilité de créer des "Tableaux Croisés Asymétriques". Par exemple; en contrôle de gestion il arrive souvent qu'on ait besoin d'avoir des tableaux présentant en colonne un croisement entre une date et des scénarios précis différents suivant la date (S1 2009 et Scénario Réel uniquement, S2 2009 et Scénario Budget uniquement). Ce tableau est asymétrique car il n'affiche pas tous les scénarios existant sous une date précise comme le ferait par défaut un tableau croisé dynamique: (S1 2009 et Scénarios Réels et Budget, S2 2009 et Scénarios Réels et Budget).
Enfin, pour les utilisateurs les plus avancés il est possible d'écrire directement ses named sets en MDX.
Tous ces points font l'objet d'un très bon post bien détaillé, publié (en anglais) par l'équipe du produit.
mercredi 30 septembre 2009
Livre "Expert Cube Development with SSAS 2008"
Un livre dont je viens de finir la lecture et qui m'a particulièrement plu:
"Expert Cube Development with Microsoft SQL Server 2008 Analysis Services".

Vous êtes peut être déjà tombés sur l'article de François sur le même sujet mais je tenais à en écrire un deuxième pour confirmer la qualité du bouquin. Il mérite bien un peu de pub :)
Sujet
Comme son nom l'indique, le livre traite d'Analysis Services (SSAS) 2008. Son originalité vient du public visé. Il ne s'agit pas ici de former une personne découvrant la solution mais plutôt de permettre à un professionnel utilisant ou ayant déjà utilisé SSAS de se perfectionner et d'appliquer certaines best practices mises en avant par les auteurs suite aux nombreux projets BI MS auxquels ils ont participé. C'est donc cet aspect "retour d'expérience" qui le caractérise et qui m'a d'ailleurs poussé à en faire l'acquisition.
Bien qu'écrit en anglais, la lecture reste assez simple. Le livre aborde des sujets comme la modélisation d'un datawarehouse en environnement MS, les slowly changing dimensions (SCD), les mesures calculées, la performance ou encore la sécurité. On trouve également tout un chapitre présentant les différentes façons d'aborder la conversion de devises dans un cube.
Auteurs
Les trois auteurs ont des noms qui vous sont peut être familiers. Ils possèdent en effet des blogs très suivis dans la communauté BI MS, il est donc probable que vous soyez déjà tombés dessus (Cliquez sur le nom de l'auteur pour visiter son blog).
35€
Environ 1 semaine pour le recevoir en tarif standard
Où
Vous pouvez commander le livre sur Packtpub ou sur Amazon.
Il n'y a par contre aucune séance de dédicaces prévue sur les Champs-Elysées, dommage!
Conclusion
Si vous travaillez de près ou de loin avec SSAS, je vous recommande donc fortement ce livre.
Si vous en êtes déjà l'heureux possesseur, n'hésitez pas à faire part de vos impressions dans les commentaires de ce billet.
Bonne lecture!
"Expert Cube Development with Microsoft SQL Server 2008 Analysis Services".

Vous êtes peut être déjà tombés sur l'article de François sur le même sujet mais je tenais à en écrire un deuxième pour confirmer la qualité du bouquin. Il mérite bien un peu de pub :)
Sujet
Comme son nom l'indique, le livre traite d'Analysis Services (SSAS) 2008. Son originalité vient du public visé. Il ne s'agit pas ici de former une personne découvrant la solution mais plutôt de permettre à un professionnel utilisant ou ayant déjà utilisé SSAS de se perfectionner et d'appliquer certaines best practices mises en avant par les auteurs suite aux nombreux projets BI MS auxquels ils ont participé. C'est donc cet aspect "retour d'expérience" qui le caractérise et qui m'a d'ailleurs poussé à en faire l'acquisition.
Bien qu'écrit en anglais, la lecture reste assez simple. Le livre aborde des sujets comme la modélisation d'un datawarehouse en environnement MS, les slowly changing dimensions (SCD), les mesures calculées, la performance ou encore la sécurité. On trouve également tout un chapitre présentant les différentes façons d'aborder la conversion de devises dans un cube.
Auteurs
Les trois auteurs ont des noms qui vous sont peut être familiers. Ils possèdent en effet des blogs très suivis dans la communauté BI MS, il est donc probable que vous soyez déjà tombés dessus (Cliquez sur le nom de l'auteur pour visiter son blog).
- Chris Webb: Consultant et formateur en Angleterre.
- Alberto Ferrari: Consultant et formateur en Italie.
- Marco Russo: Consultant et formateur en Italie
Combien
350 Pages35€
Environ 1 semaine pour le recevoir en tarif standard
Où
Vous pouvez commander le livre sur Packtpub ou sur Amazon.
Il n'y a par contre aucune séance de dédicaces prévue sur les Champs-Elysées, dommage!
Conclusion
Si vous travaillez de près ou de loin avec SSAS, je vous recommande donc fortement ce livre.
Si vous en êtes déjà l'heureux possesseur, n'hésitez pas à faire part de vos impressions dans les commentaires de ce billet.
Bonne lecture!
mardi 29 septembre 2009
Gemini: Un rapport SSRS comme source de données
Une fonctionnalité dont je n'ai pas parlé dans mes précédents billets mais qui est une originalité de Gemini: la possibilité d'utiliser un rapport SSRS comme source de données.
Gemini étant destiné en premier lieu aux utilisateurs fonctionnels, ceux ci n'ont pas forcément un accès aux bases de données. Un moyen simple d'obtenir des données fiables peut donc être de se fonder sur un rapport Reporting Services déjà existant (graphes, tableaux ou matrices).
Cette fonctionnalité est présentée dans le dernier article du blog de l'équipe Gemini (en anglais)
Également une vidéo (en anglais) publiée par Donald Farmer (Equipe Gemini) permet d'en voir une démonstration.
Gemini étant destiné en premier lieu aux utilisateurs fonctionnels, ceux ci n'ont pas forcément un accès aux bases de données. Un moyen simple d'obtenir des données fiables peut donc être de se fonder sur un rapport Reporting Services déjà existant (graphes, tableaux ou matrices).
Cette fonctionnalité est présentée dans le dernier article du blog de l'équipe Gemini (en anglais)
Également une vidéo (en anglais) publiée par Donald Farmer (Equipe Gemini) permet d'en voir une démonstration.
mercredi 2 septembre 2009
Exemple d'application Gemini
Après avoir décrit certaines fonctionnalités de Gemini dans mon dernier billet, je vous propose de découvrir à quoi pourront ressembler des applications construites avec ce nouvel outil Microsoft.
En cette période de retour de vacances, j'ai choisi le thème des voyages avec une analyse des vols au départ de l'aéroport Roissy Charles de Gaule (CDG). J'ai récolté des données sur le site FilghtStats sur une journée complète qui ont constituées ma table de faits (Numéro du vol, heure prévue de décollage, heure réelle de décollage, code de l'aéroport de destination etc.). Afin d'avoir des analyses un peu plus complètes, j'ai intégré la liste des aéroports mondiaux avec leur code, ville, pays; des données sur les numéros de vols et leur compagnies aériennes et enfin des données météorologiques (METAR) de l'aéroport Charles de Gaule ce même jour.
L'intégration dans Gemini a été assez simple. J'ai tout simplement copié les données dans les tables Gemini. J'ai donc eu 4 onglets (tables): Airline, Airport, Fact, Metar (Météo).
L'étape suivante à consistée à faire le lien entre ces tables. Par exemple, lier le code de l'aéroport de destination dans la table des faits au code dans ma table Airport. Cette création des clés a permis de détecter des doublons dans mes tables dimensions et ainsi de le nettoyer.
J'ai ensuite créé quelques colonnes calculées notamment pour avoir les retards (en minute), le nombre total de vols de la journée ou encore convertir la température de Fahrenheit à Celcius.






En cette période de retour de vacances, j'ai choisi le thème des voyages avec une analyse des vols au départ de l'aéroport Roissy Charles de Gaule (CDG). J'ai récolté des données sur le site FilghtStats sur une journée complète qui ont constituées ma table de faits (Numéro du vol, heure prévue de décollage, heure réelle de décollage, code de l'aéroport de destination etc.). Afin d'avoir des analyses un peu plus complètes, j'ai intégré la liste des aéroports mondiaux avec leur code, ville, pays; des données sur les numéros de vols et leur compagnies aériennes et enfin des données météorologiques (METAR) de l'aéroport Charles de Gaule ce même jour.
L'intégration dans Gemini a été assez simple. J'ai tout simplement copié les données dans les tables Gemini. J'ai donc eu 4 onglets (tables): Airline, Airport, Fact, Metar (Météo).
L'étape suivante à consistée à faire le lien entre ces tables. Par exemple, lier le code de l'aéroport de destination dans la table des faits au code dans ma table Airport. Cette création des clés a permis de détecter des doublons dans mes tables dimensions et ainsi de le nettoyer.
J'ai ensuite créé quelques colonnes calculées notamment pour avoir les retards (en minute), le nombre total de vols de la journée ou encore convertir la température de Fahrenheit à Celcius.
Fenêtre d'intégration des données de Gemini:

Une fois les données intégrées, on ferme la fenêtre d'intégration des données et on revient au fichier Excel classique, ce qui constituera in fine le rapport.
On profite de l'intégration dans Excel en créant librement des onglets. Cela dit, je vous conseille d'en maîtrise le nombre si vous ne voulez pas vous y perdre, ou si vous souhaitez que quelqu'un puisse facilement reprendre le fichier après vous.
J'ai donc créé un premier onglet de présentation de l'application, qui n'est pas lié aux données mais qui a pour but d'accueillir l'utilisateur du rapport.
Onglet "Welcome":

J'ai ensuite créé 3 autres onglets, chacun correspondant à un type d'analyse: "By Destination", "By Airline" et "By Hour". Afin de rendre l'expérience utilisateur encore plus interactive, j'ai ajouté des Slicers (nouveauté Excel 2010) qui permettent de filtrer les données en un simple click et de façon très visuelle. La particularité de ces slicers est qu'ils peuvent être liés avec un ou plusieurs éléments du fichier. Ainsi, si l'utilisateur sélectionne une compagnie ou une heure dans un onglet, ce choix sera propagé automatiquement sur les onglets suivants.
Onglet "By Destination":

Onglet "By Airline":

Onglet "By Hour":

Une fois le document créé, il est sauvegardé comme un fichier Excel 2010 classique, avec une extension .xlsx.
Il est possible ensuite de soit envoyer ce fichier à un autre utilisateur, soit le partager de façon plus globale au sein de l'entreprise via un portail Sharepoint 2010. Je n'ai pas encore pu tester cette intégration mais elle s'annonce des plus prometteuses d'après les premières informations qui commencent à émerger.
Exemple d'intégration de Gemini dans Sharepoint 2010:

Source: Blog de l'équipe Gemini
C'était donc une première ébauche d'application Gemini. Bien qu'en version bêta, l'outil présente déjà des fonctionnalités assez intéressantes. facile d'utilisation, il sera intéressant d'en voir l'adoption par les utilisateurs à sa sortie l'année prochaine.
C'était donc une première ébauche d'application Gemini. Bien qu'en version bêta, l'outil présente déjà des fonctionnalités assez intéressantes. facile d'utilisation, il sera intéressant d'en voir l'adoption par les utilisateurs à sa sortie l'année prochaine.
jeudi 20 août 2009
Gemini Vs QlikView
La rentrée s'annonce plutôt intéressante compte tenu des différentes CTP sorties ces derniers jours. Entre autre, SQL Server 2008 R2 dont le très attendu Gemini, Office 2010, SharePoint 2010. Bref, de longues heures de beta testing en perspective.
Parmi ces nouveautés, on trouve donc une première version CTP du projet Gemini. Présenté pour la première fois à la Microsoft BI Conference en octobre dernier, ce nouvel outil fait parti de la 3ème génération Business Intelligence .
Gemini est un add-in Excel principalement destiné aux utilisateurs fonctionnels et permettant d'analyser de grands volumes de données. A la différence d'un cube, les données sont traitées en mémoire (in-memory), ce qui grâce à un système de compression par colonne, propose de très bons temps de réponse.
Microsoft vient donc concurrencer QlikTech et son produit phare: QlikView.
Ayant pas mal travaillé sur QlikView ces derniers temps, je vous propose de commencer un comparatif entre les deux produits, tout en gardant en tête que Gemini reste en version beta.
Général
De façon générale, le principal avantage de Gemini est son intégration dans Excel. C'est un outil connu de tous ou presque et qui ne nécessite donc pas de formation particulière. Inconvénient, Gemini ne fonctionne pour le moment qu'avec Office 2010.
Onglet Gemini dans Excel 2010:
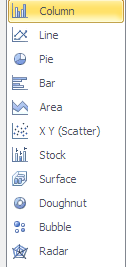
QlikView propose une gamme de graphe équivalente avec la particularité de proposer en plus des jauges et les blocs (Cf cartes de performance dans Proclarity). Certains autres éléments proposés par QlikView comme les glissières ou les tableaux statistiques mériteraient leur place dans Gemini.
Gemini concurrence sérieusement QlikView dans le domaine de l'associativité. Grâce à l'utilisation des slicers, nouveauté des tableaux croisés Excel 2010, on peut sélectionner rapidement et simplement les données qui nous intéressent , ce qui a pour conséquence de mettre à jour le reste des zones de sélection, sans hiérarchies prédéfinies. Par exemple, en sélectionnant une année, la liste des mois disponibles est mise à jour ainsi que des monnaies présentes dans les tables de fait durant cette période.
Petite différence cependant, dans QlikView quand on sélectionne un élément, la sélection est globale sur l'ensembles de pages et des rapports du fichier. Sur Excel, la sélection ,n'est à première vue valable que sur le graphe ou tableau concerné. Je n'ai pas encore vu s'il est possible d'étendre la portée de la sélection…à suivre.
Publication
Une fois créés, les rapports Gemini et QlikView peuvent être diffusés afin de les partager avec d'autres utilisateurs. Le principe est le même, seules les plateformes diffèrent.
Les rapports Gemini sont diffusés via un serveur Sharepoint 2010 (du moins dans la version beta).
Les rapports QlikView sont diffusés via un serveur QlikView qui peuvent éventuellement par la suite être inclus dans un site Sharepoint via une Webpart.
Conclusion
Gemini vient donc concurrencer sérieusement QlikView. Destiné aux utilisateurs fonctionnels, il est assez simple d'utilisation et directement intégré dans Excel.
Parmi ces nouveautés, on trouve donc une première version CTP du projet Gemini. Présenté pour la première fois à la Microsoft BI Conference en octobre dernier, ce nouvel outil fait parti de la 3ème génération Business Intelligence .
Gemini est un add-in Excel principalement destiné aux utilisateurs fonctionnels et permettant d'analyser de grands volumes de données. A la différence d'un cube, les données sont traitées en mémoire (in-memory), ce qui grâce à un système de compression par colonne, propose de très bons temps de réponse.
Microsoft vient donc concurrencer QlikTech et son produit phare: QlikView.
Ayant pas mal travaillé sur QlikView ces derniers temps, je vous propose de commencer un comparatif entre les deux produits, tout en gardant en tête que Gemini reste en version beta.
Général
De façon générale, le principal avantage de Gemini est son intégration dans Excel. C'est un outil connu de tous ou presque et qui ne nécessite donc pas de formation particulière. Inconvénient, Gemini ne fonctionne pour le moment qu'avec Office 2010.
Onglet Gemini dans Excel 2010:

QlikView est quant à lui un outil client spécifique, indépendant, et nécessite un temps d'adaptation et de formation (comme pour tout nouvel outil).
Application QlikView:


Manipulation des données
Même si ces deux outils permettent de charger et manipuler des données, il ne peuvent en aucun cas se substituer à de vrais ETL. Les données utilisées sont censées avoir déjà été "nettoyées", le plus souvent issues d'un datawarehouse ou datamart.
Des deux outils, c'est Gemini qui semble le plus user-friendly. En effet, aucun script technique n'est présenté à l'utilisateur pour le chargement des données. Même si dans le cas de QlikView ce script peut être rempli automatiquement via des assistants de configuration, un utilisateur réticent à la technique peut être dérouté. Gemini est donc plus transparent…bon point pour un outil destiné à des personnes plutôt fonctionnelles.
Même si ces deux outils permettent de charger et manipuler des données, il ne peuvent en aucun cas se substituer à de vrais ETL. Les données utilisées sont censées avoir déjà été "nettoyées", le plus souvent issues d'un datawarehouse ou datamart.
Des deux outils, c'est Gemini qui semble le plus user-friendly. En effet, aucun script technique n'est présenté à l'utilisateur pour le chargement des données. Même si dans le cas de QlikView ce script peut être rempli automatiquement via des assistants de configuration, un utilisateur réticent à la technique peut être dérouté. Gemini est donc plus transparent…bon point pour un outil destiné à des personnes plutôt fonctionnelles.
Script de chargement QlikView:
Concernant les liaisons entre les tables, Gemini et QlikView ont deux approches assez différentes. QlikView crée ces liaisons par homonymies. Autrement dit, une liaison est crée dès que deux champs de deux tables différentes ont le même nom. Cette méthode a ses avantages et ses inconvénient. Avantage, pas de lien à spécifier manuellement ce qui peut faire gagner beaucoup de temps. Inconvénient, de mauvaises liaisons peuvent se créer, voir des liaisons circulaires si on est pas vigilent dans le nommage de ses colonnes…
Gemini a donc une approche différente. Si on utilise une base existante, les clés étrangères sont conservées. Il faudra cependant créer manuellement les liaisons manquantes, notamment avec les sources complémentaires utilisées.

Concernant les liaisons entre les tables, Gemini et QlikView ont deux approches assez différentes. QlikView crée ces liaisons par homonymies. Autrement dit, une liaison est crée dès que deux champs de deux tables différentes ont le même nom. Cette méthode a ses avantages et ses inconvénient. Avantage, pas de lien à spécifier manuellement ce qui peut faire gagner beaucoup de temps. Inconvénient, de mauvaises liaisons peuvent se créer, voir des liaisons circulaires si on est pas vigilent dans le nommage de ses colonnes…
Gemini a donc une approche différente. Si on utilise une base existante, les clés étrangères sont conservées. Il faudra cependant créer manuellement les liaisons manquantes, notamment avec les sources complémentaires utilisées.
Gestion des relations entre tables dans Gemini:
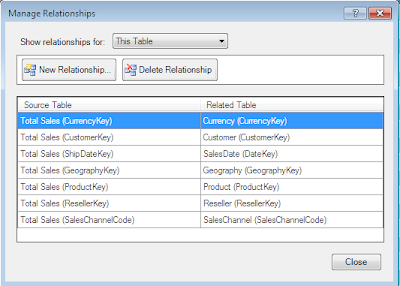
Elément appréciable dans Gemini, la possibilité de voir directement le résultat des colonnes calculées qu'on rajoute sans tout recharger. On détecte ainsi immédiatement les erreurs dans les formules saisies.
Cependant, un des manques de Gemini par rapport à QlikView (du moins dans cette version beta) est de pouvoir visualiser de manière graphique les tables et leurs liaisons. Dans QlikView, cela est réalisable grâce à la visionneuse de tables, un peu à la manière des diagrammes dans SQL Server.

Elément appréciable dans Gemini, la possibilité de voir directement le résultat des colonnes calculées qu'on rajoute sans tout recharger. On détecte ainsi immédiatement les erreurs dans les formules saisies.
Cependant, un des manques de Gemini par rapport à QlikView (du moins dans cette version beta) est de pouvoir visualiser de manière graphique les tables et leurs liaisons. Dans QlikView, cela est réalisable grâce à la visionneuse de tables, un peu à la manière des diagrammes dans SQL Server.
Visionneuse de tables dans QlikView:
Création des objets graphiques
In fine, le but de ces deux outils est de fournir une visualisation des données sélectionnées dans la 1ère partie.
Globalement, tous deux répondent à la plupart des besoins. Les résultats sont plutôt esthétiques, attrayant pour le consommateur du rapport.
Gemini profite de son intégration dans Excel qui gère déjà un grand nombre de graphes dont voici une liste non exhaustive:

Création des objets graphiques
In fine, le but de ces deux outils est de fournir une visualisation des données sélectionnées dans la 1ère partie.
Globalement, tous deux répondent à la plupart des besoins. Les résultats sont plutôt esthétiques, attrayant pour le consommateur du rapport.
Gemini profite de son intégration dans Excel qui gère déjà un grand nombre de graphes dont voici une liste non exhaustive:

QlikView propose une gamme de graphe équivalente avec la particularité de proposer en plus des jauges et les blocs (Cf cartes de performance dans Proclarity). Certains autres éléments proposés par QlikView comme les glissières ou les tableaux statistiques mériteraient leur place dans Gemini.
Types de graphiques dans QlikView:


Gemini concurrence sérieusement QlikView dans le domaine de l'associativité. Grâce à l'utilisation des slicers, nouveauté des tableaux croisés Excel 2010, on peut sélectionner rapidement et simplement les données qui nous intéressent , ce qui a pour conséquence de mettre à jour le reste des zones de sélection, sans hiérarchies prédéfinies. Par exemple, en sélectionnant une année, la liste des mois disponibles est mise à jour ainsi que des monnaies présentes dans les tables de fait durant cette période.
Petite différence cependant, dans QlikView quand on sélectionne un élément, la sélection est globale sur l'ensembles de pages et des rapports du fichier. Sur Excel, la sélection ,n'est à première vue valable que sur le graphe ou tableau concerné. Je n'ai pas encore vu s'il est possible d'étendre la portée de la sélection…à suivre.
[edit: Après quelques tests supplémentaires, il est finalement possible d'étendre la portée de la sélection d'un slicer]
Exemple de rapport Gemini:


Publication
Une fois créés, les rapports Gemini et QlikView peuvent être diffusés afin de les partager avec d'autres utilisateurs. Le principe est le même, seules les plateformes diffèrent.
Les rapports Gemini sont diffusés via un serveur Sharepoint 2010 (du moins dans la version beta).
Les rapports QlikView sont diffusés via un serveur QlikView qui peuvent éventuellement par la suite être inclus dans un site Sharepoint via une Webpart.
Conclusion
Gemini vient donc concurrencer sérieusement QlikView. Destiné aux utilisateurs fonctionnels, il est assez simple d'utilisation et directement intégré dans Excel.
QlikView quant à lui garde une petite avance grâce à un choix d'objets graphiques un peu plus large et une personnalisation des scripts de chargement un peu plus forte. Mais ce dernier argument ne pèse peut être pas autant pour un utilisateur non technique qui recherche avant tout la simplicité.
N'oublions pas que Gemini reste une beta de version 1 ( Nb: QlikView est en version 9). Il reste donc surement des choses à découvrir avant la sortie de la version finale prévue pour le premier semestre 2010... To be continued...
N'oublions pas que Gemini reste une beta de version 1 ( Nb: QlikView est en version 9). Il reste donc surement des choses à découvrir avant la sortie de la version finale prévue pour le premier semestre 2010... To be continued...
lundi 13 juillet 2009
SSRS 2008 et la fonctionnalité "Repeat Header"
Pour poursuivre dans la lancée de l'article publié par Gurvan il y a quelques jours, voici une autre petite anomalie apparue dans la version 2008 de Reporting Services.



Dans les propriétés d'une table ou d'une matrix, vous pouvez préciser si vous désirez que l'entête des colonnes (et/ou des lignes) se répète sur chaque page. Pour les matrices, pas de problème, l'option est bien prise en compte en 2008. Ce n'est pas le cas pour les tables ne possédant pas de groupe sur les colonnes. L'option est ignorée.

Il existe heureusement une façon de contourner le problème. Dans la fenêtre de gestion des groupes, passez en mode "avancé". Vous verrez alors apparaître les groupes "statiques" qui étaient jusque là masqués.

Cliquez sur le groupe statique que vous souhaitez voir se répéter sur chaque page et configurer la valeur de la propriété "RepeatOnNewPage" de ce groupe à "true".

Le problème est alors réglé et les entêtes de colonnes de la table se répéteront bien sur chaque nouvelle page. Dommage que l'option ne soit pas directement prise en compte au niveau de l'interface graphique, le contournement n'est cependant pas trop compliqué.
dimanche 5 juillet 2009
CUBIM & Cubes Asymétriques
Il y a quelques semaines, j'ai assisté pour la première fois à une réunion du club des utilisateurs de la Business Intelligence Microsoft: CUBIM.

Loin d'être un groupe de support anonyme à l'arrêt de la consommation de BI ("Bonjour je m'appelle Aurélien et j'ai pas construit de cube depuis 2 jours"), ce club est destiné aux échanges sur ces technologies. C'est l'occasion notammement d'avoir des retours projets mais aussi des présentations de fonctionnalités creusées par tel ou tel membre.
C'est au cours de cette réunion que j'ai rencontré Renaud Harduin qui m'a parlé d'un article sur les cubes assymétriques qu'il a publié l'année dernière.
C'est un sujet assez intéressant et peu documenté, la possibilité de mettre en place des cubes ayant des partitions "actuelle" avec une granularité à la journée et une partition "historique" avec une granularité au mois. Cet article est donc un tutoriel qui vous permettra de mettre en place facilement ce mécanisme.
Vous trouverez plus de détails ICI. Bonne lecture!

Loin d'être un groupe de support anonyme à l'arrêt de la consommation de BI ("Bonjour je m'appelle Aurélien et j'ai pas construit de cube depuis 2 jours"), ce club est destiné aux échanges sur ces technologies. C'est l'occasion notammement d'avoir des retours projets mais aussi des présentations de fonctionnalités creusées par tel ou tel membre.
C'est au cours de cette réunion que j'ai rencontré Renaud Harduin qui m'a parlé d'un article sur les cubes assymétriques qu'il a publié l'année dernière.
C'est un sujet assez intéressant et peu documenté, la possibilité de mettre en place des cubes ayant des partitions "actuelle" avec une granularité à la journée et une partition "historique" avec une granularité au mois. Cet article est donc un tutoriel qui vous permettra de mettre en place facilement ce mécanisme.
Vous trouverez plus de détails ICI. Bonne lecture!
dimanche 28 juin 2009
Visualiser l'odre du tri de votre collation SQL Server
Petite astuce pour trouver le caractère suivant le "z" lors d'un tri sur votre base de données.
Cela peut s'avérer utile si vous souhaitez avoir un membre qui apparaisse toujours en dernier lorsque vous classez les membres d'une table par ordre alphabétique (sans la nécessité d'une colonne supplémentaire de tri).
Pour retrouver le classement des caractères sur votre base, utilisez la requête suivante:
CREATE TABLE T1 ( ID int, CARACTERE AS char(ID))
DECLARE @I AS Int
SET @I=1
WHILE (@I <256)
BEGIN
INSERT INTO T1(ID) VALUES (@I)
SET @I = @I+1
END
SELECT * FROM T1 ORDER BY CARACTERE go
DROP TABLE T1
Réponse (sur une base en SQL_Latin1_General_CP1_CS_AS): Il existe donc 4 caractères étant classés après le "z" dans un tri. Dans l'ordre: Ð, ð, Þ et þ.
Bien sûr, cela dépend de la collation définie sur votre base. Par exemple la même requête en French_CI_AS donnera le résultat suivant: Ž et ž
Pour information, Ð, ð, Þ et þ sont des lettres utilisées dans l'alphabet islandais...j'aurais pu les chercher longtemps sans cette requête!
Cela peut s'avérer utile si vous souhaitez avoir un membre qui apparaisse toujours en dernier lorsque vous classez les membres d'une table par ordre alphabétique (sans la nécessité d'une colonne supplémentaire de tri).
Pour retrouver le classement des caractères sur votre base, utilisez la requête suivante:
CREATE TABLE T1 ( ID int, CARACTERE AS char(ID))
DECLARE @I AS Int
SET @I=1
WHILE (@I <256)
BEGIN
INSERT INTO T1(ID) VALUES (@I)
SET @I = @I+1
END
SELECT * FROM T1 ORDER BY CARACTERE go
DROP TABLE T1
Réponse (sur une base en SQL_Latin1_General_CP1_CS_AS): Il existe donc 4 caractères étant classés après le "z" dans un tri. Dans l'ordre: Ð, ð, Þ et þ.
Bien sûr, cela dépend de la collation définie sur votre base. Par exemple la même requête en French_CI_AS donnera le résultat suivant: Ž et ž
Pour information, Ð, ð, Þ et þ sont des lettres utilisées dans l'alphabet islandais...j'aurais pu les chercher longtemps sans cette requête!
mardi 23 juin 2009
SSIS 2008 a fait le ménage
Petite surprise en appliquant à une base SQL Server 2008 un script créé en 2005 et qui manipulait les vues et fonctions systeme sysdtspackagefolders90, sysdtspackages90, sp_dts_deletepackage, sp_dts_deletefolder et autres... Celles ci n'existent plus en 2008! Pour être plus exact, elles ont été renommées. Microsoft a en effet fait du ménage dans ces labels qui faisaient référence à la version 2000 de l'ETL (DTS). Vous utiliserez donc désormais les vues et fonctions systeme sysssipackages, sysssispackagefolders, sp_ssis_deletefolder, sp_ssis_deletepackage etc.
jeudi 18 juin 2009
Financial Planning Accelerator
Une annonce parue aujourd'hui sur le site Partners de Microsoft et commentée sur le très bon blog de Chriss Webb: PerformancePoint Planning est de retour dans une version quasi open-source!
Finalement, Microsoft a entendu les appels de ses partenaires (cf post du mois de fevrier) et permet donc de reprendre le projet planning et d'y apporter sa touche personnelle. Les utilisateurs eux, pourrons bénéficier de ce produit via la licence Sharepoint qui donne accès par la même occasion à PerformancePoint Services Monitoring & Analytics (ex Proclarity).
Finalement, Microsoft a entendu les appels de ses partenaires (cf post du mois de fevrier) et permet donc de reprendre le projet planning et d'y apporter sa touche personnelle. Les utilisateurs eux, pourrons bénéficier de ce produit via la licence Sharepoint qui donne accès par la même occasion à PerformancePoint Services Monitoring & Analytics (ex Proclarity).
mercredi 17 juin 2009
Kimball Slowly Changing Dimension (SCD)
L'une des composantes d'un projet BI est la gestion de ce qu'on appelle les "Slowly Changing Dimension" (SCD) ou "dimensions à variation lente". L'enjeu est le suivant, historiser ou non les attributs d'une dimension et si oui, dans quelle mesure. Il existe plusieurs types de SCD, numérotés de 0 à 6, chacun permettant de couvrir un cas de figure particulier, les plus couramment utilisés étant les types 1 et 2.
Prenons l'exemple d'une dimension employé, chaque employé occupant un poste précis. Une SCD de type 1 ne garderait dans le datawarehouse que le dernier poste occupé par un employé. Une SCD de type 2 permettrait elle de garder un historique des postes occupés par l'employé, en précisant les dates de début et de fin de chacun de ces postes.
Il existe différentes méthodes pour appliquer ces principes dans un lot de chargement Integration Services, que ce soit à l'aide de composants de recherche (lookup) ou du composant SSIS SCD. Il existe cependant une alternative gratuite et performante: Le Kimball Slowly Changing Dimension component. Ce composant développé par Todd McDermid et disponible gratuitement sur CodePlex permet de gérer très facilement le chargement des SCD de type 1 et 2.
Si vous souhaitez l'essayer, la version 1.4 est disponible ici, je vous le conseille vivement!
Prenons l'exemple d'une dimension employé, chaque employé occupant un poste précis. Une SCD de type 1 ne garderait dans le datawarehouse que le dernier poste occupé par un employé. Une SCD de type 2 permettrait elle de garder un historique des postes occupés par l'employé, en précisant les dates de début et de fin de chacun de ces postes.
Il existe différentes méthodes pour appliquer ces principes dans un lot de chargement Integration Services, que ce soit à l'aide de composants de recherche (lookup) ou du composant SSIS SCD. Il existe cependant une alternative gratuite et performante: Le Kimball Slowly Changing Dimension component. Ce composant développé par Todd McDermid et disponible gratuitement sur CodePlex permet de gérer très facilement le chargement des SCD de type 1 et 2.

Si vous souhaitez l'essayer, la version 1.4 est disponible ici, je vous le conseille vivement!
mardi 31 mars 2009
Sum Distinct avec SSRS
Reporting Services (SSRS) 2005 propose de nombreuses fonctions d'agrégation dont Sum, Min, Max, Avg, Count, Count distinct etc.

Imaginons qu'on ait une requête qui ramène une liste combinant des employés, leurs spécialités, leur département et leur salaire. On aura donc une spécialité d'employé par ligne et donc potentiellement plusieurs lignes pour un même employé.

=Sum(Code.SumDistinct(01, Fields!EmployeeId.Value, Fields!Salaire.Value))

Malheureusement il arrive souvent qu'on ait besoin d'une autre fonction qui n'est pas fournie par défaut: Sum Distinct. Ce billet vous montre donc comment l'implémenter dans votre rapport.
Imaginons qu'on ait une requête qui ramène une liste combinant des employés, leurs spécialités, leur département et leur salaire. On aura donc une spécialité d'employé par ligne et donc potentiellement plusieurs lignes pour un même employé.
Si on désire réaliser un rapport avec un regroupement par département affichant le nombre d'employés à ce niveau agrégé, alors on peut utiliser la fonction CountDistinct(Fields!EmployeeID.value) dans la case correspondante, ce qui ramène le bon résultat.
Le problème apparaît lorsqu'on désire par exemple calculer la somme des salaires d'un département. On pourrait rajouter un champ dans la requête qui serait le résultat d'une sous requête et ramènerait le TotalSalaireDepartement pour chaque département. C'est une solution qui est peu envisageable si le nombre de champs à rajouter est élevé. D'où l'idée de cette fonction SumDistinct qui permet de récupérer le résultat grâce à un petit bout de code Vb.
Pour ajouter la nouvelle fonction, aller dans l'onglet "code" des propriétés du rapport:

Il ne reste plus qu'à appeler la fonction dans les cases du rapport.
SumDistinct(Mesure, ID, Valeur)
Ce qui donne pour cette exemple au niveau d'une ligne département:
=Sum(Code.SumDistinct(01, Fields!EmployeeId.Value, Fields!Salaire.Value))
Remarquez dans le code la clé de la HashTable qui est composée d'une Mesure (01 pour Salaire) et d'un ID (EmployeeID). Cette astuce permet de pouvoir réutiliser la même fonction pour des mesures différentes, par exemple 01 pour le salaire, 02 pour le poids de l'employé ou encore 03 pour l'âge de l'employé, sous réserve que les valeurs agrégées au niveau département de ces dernières mesures aient un intérêt quelconque:)
mercredi 25 mars 2009
Installer Reporting Services sur Windows Server Web Edition
Voici un problème auquel j'ai été confronté récemment chez un client, installer Reporting Services sur une Web edition de Windows server.
Si vous lancez la procédure classique d'installation SQL Server, vous réaliserez vite que le nombre de possibilités est assez limité. Vous ne pouvez en effet qu'installer les outils clients sur cette version de Windows Server (les autres composants étant grisés). Il est en effet impossible d'installer un moteur de base de données sur cette édition. Cela dit, dans mon cas, le but était seulement d'installer la partie applicative de Reporting Services, les bases de métadata étant stockées sur un autre serveur dédié aux bases de données.
La bonne nouvelle est qu'il est possible d'installer Reporting Services même si le wizzard classique d'installation ne le permet pas. L'astuce est la suivante: lancer le fichier "SqlRun_RS.msi" qui est situé dans le répertoire "\Servers\Setup" du CD SQL Server 2005.
Une fois l'installation terminée, vous pouvez configurer votre serveur de rapport en lançant "Reporting Services Configuration". C'est à travers cette interface que vous chosirez par exemple le serveur qui accueillera vos bases métadata "ReportServer" et "ReportServerTempDB".
Si vous lancez la procédure classique d'installation SQL Server, vous réaliserez vite que le nombre de possibilités est assez limité. Vous ne pouvez en effet qu'installer les outils clients sur cette version de Windows Server (les autres composants étant grisés). Il est en effet impossible d'installer un moteur de base de données sur cette édition. Cela dit, dans mon cas, le but était seulement d'installer la partie applicative de Reporting Services, les bases de métadata étant stockées sur un autre serveur dédié aux bases de données.
La bonne nouvelle est qu'il est possible d'installer Reporting Services même si le wizzard classique d'installation ne le permet pas. L'astuce est la suivante: lancer le fichier "SqlRun_RS.msi" qui est situé dans le répertoire "\Servers\Setup" du CD SQL Server 2005.
Une fois l'installation terminée, vous pouvez configurer votre serveur de rapport en lançant "Reporting Services Configuration". C'est à travers cette interface que vous chosirez par exemple le serveur qui accueillera vos bases métadata "ReportServer" et "ReportServerTempDB".
samedi 14 février 2009
Le code de Planning bientôt sur codeplex?
Comme je vous l'annonçais dans mon précédent billet, Microsoft n'exclut pas la possibilité de mettre le code de PerformancePoint Planning à disposition sur Codeplex.
C'est pour l'instant une idée parmi d'autres, qui ne serait mise en oeuvre qu'après la sortie du SP3 en milieu d'année.
J'en ai discuté avec différentes personnes et j'ai eu des retours assez variés. Certains y voient la possibilité de faire évoluer l'application et de continuer à la proposer à des clients pour des problématiques de writeback via Excel avec workflow, d'autres sont pour...au cas où..., d'autres encore préfèrent passer à autre chose. D'où l'idée de lancer ce petit sondage pour savoir ce que vous en pensez. Celui ci est disponible sur la droite de cet écran.
C'est pour l'instant une idée parmi d'autres, qui ne serait mise en oeuvre qu'après la sortie du SP3 en milieu d'année.
J'en ai discuté avec différentes personnes et j'ai eu des retours assez variés. Certains y voient la possibilité de faire évoluer l'application et de continuer à la proposer à des clients pour des problématiques de writeback via Excel avec workflow, d'autres sont pour...au cas où..., d'autres encore préfèrent passer à autre chose. D'où l'idée de lancer ce petit sondage pour savoir ce que vous en pensez. Celui ci est disponible sur la droite de cet écran.
Les réponses disponibles sont les suivantes: (Update: Résultats)
- C'est une super nouvelle, j'attends ça avec impatience: 44%
- Pourquoi pas, ça peut toujours être utile...un jour: 44%
- C'est pas la peine, je préfère oublier planning: 12%
Bon vote!
jeudi 12 février 2009
La nouvelle roadmap BI de Microsoft
La nouvelle concernant le futur de l’offre PerformancePoint Server est tombée il y a maintenant quelques semaines. Il a été intéressant d’observer les réactions suite à cette annonce que ce soit parmi mes collègues, sur la blogosphère ou chez les clients. De la déception pour certains, au soulagement de ne pas s’être investi dans la solution pour d’autres, ce fut également l’occasion de lire et d’entendre diverses informations, souvent contradictoires, sur le devenir du produit.
Hier s’est tenue, au centre de conférences de Microsoft à Paris, une réunion durant laquelle nous avons enfin pu avoir quelques réponses (ou tout au moins des pistes) à des questions laissées en suspens. Microsoft semble avoir pris la chose plutôt sérieusement. Ce ne sont pas moins de 3 personnes de Corp. (Microsoft US) qui sont intervenues pendant cette présentation. Il y avait Karl Leigh (Global BI Partner Strategy Director), Ben Tamblyn (Global BI Partner Strategy BDM) et Guy Weismantel (Marketing Director). Dure concurrence pour la session aux techdays consacrée à Analysis Services 2008 qu’animaient deux de mes amis et collègues, Romuald et François, à la même heure.
Hier s’est tenue, au centre de conférences de Microsoft à Paris, une réunion durant laquelle nous avons enfin pu avoir quelques réponses (ou tout au moins des pistes) à des questions laissées en suspens. Microsoft semble avoir pris la chose plutôt sérieusement. Ce ne sont pas moins de 3 personnes de Corp. (Microsoft US) qui sont intervenues pendant cette présentation. Il y avait Karl Leigh (Global BI Partner Strategy Director), Ben Tamblyn (Global BI Partner Strategy BDM) et Guy Weismantel (Marketing Director). Dure concurrence pour la session aux techdays consacrée à Analysis Services 2008 qu’animaient deux de mes amis et collègues, Romuald et François, à la même heure.
- Planning
Commençons par la partie Planning. Comme vous avez pu le lire depuis le 22 janvier, ce module va être arrêté. Un Service Pack (SP3) sera fourni en cours d’année et aucun autre investissement ne sera réalisé de la part de Microsoft dans une version « stand alone » du produit. C'est une décision surprenante de la part de Microsoft étant donnés les investissements réalisés aussi bien en interne (équipes de développement, commerciaux, formations...) qu'en externe (clients, partenaires...). Même si certains signes semblaient indiquer ces derniers temps un changement de stratégie vis à vis du produit, on aurait pu s'attendre à une réorganisation avec le module planning poursuivit de façon individuelle, sans ses compagnons Monitoring et Analytics...ce n'est donc pas le cas. L’arrêt du module a été justifié assez clairement lors de la présentation par les coûts et les efforts nécessaires à la vente du produit.
Petite information interessante cependant, les personnes de Corp. n’ont pas exclu la possibilité de mettre le code de planning à disposition sur codeplex, ce qui permettrait à des partenaires de continuer à travailler sur le sujet et faire évoluer l’application…à suivre donc…
Quoi qu’il arrive, les clients existants de ce module continueront à avoir un support sur l’application pendant 10 ans (comme pour tout produit Microsoft qui s’arrête).
Il a également été évoqué la possibilité de retrouver certaines fonctionnalités de planning telles que le forecasting etc. au sein de l’ERP Microsoft qu’est « Dynamics ». A suivre également.
- PerformancePoint Services Dashboard & Scorecards et PerformancePoint Services Analytics
Passons maintenant aux deux autres modules qui composent l’offre PerformancePoint server. Monitoring et Analytics vont donc, dès le 1er avril, rejoindre l’univers Sharepoint sous le nom « PerformancePoint Services ». C’est à priori plutôt une bonne décision, qui permet à Microsoft d’intégrer encore d’avantage la BI au sein de son portail d’entreprise. Les clients s’y retrouveront également au niveau financier. En effet, si vous ne souhaitiez faire que du reporting (M&A) vous deviez quand même acheter les licences complètes de PerformancePoint Server, soit $20.000 par serveur et $195 par utilisateur. Avec l’intégration dans Sharepoint, les clients n’auront plus qu’à acheter les licences MOSS entreprise, soit $4500 pour un serveur et $160 par utilisateurs.
Le dashboard designer restera l’interface de création des scorecards et dashboards dans la prochaine version. Des évolutions du logiciel sont prévues mais les rapports créés avec la version PPS 2007 Monitoring devraient à priori être compatibles avec la version PerformancePoint Services. Un utilitaire de migration sera fourni le cas échéant.
La version Desktop de Proclarity ne devrait par contre plus évoluer. Elle restera disponible mais sous la forme qu’on connait aujourd’hui.
Cette nouvelle version du produit est donc prévue avec la sortie d’office 14, Q1 2010.
- Point complémentaire
- Le blog
Reste une question à résoudre, comment faire évoluer ce blog… Je l’avais créé au départ pour échanger sur cette nouvelle offre PerformancePoint Server. Celle-ci n’étant plus d’actualité, je vais élargir le thème de mes billets aux différents aspects que j’aborde lors de mes prestations de consulting, que ce soit Analysis Services, le MDX, SSIS, SSRS, le futur PerformancePoint Services, bref la BI MS en général. Le titre du blog devient donc plus généraliste: “La Business Intelligence Microsoft ”. Bonne lecture, stay tuned!
Inscription à :
Articles (Atom)
.png)
.png)
